
Для одного из проектов было необходимо распознать текст на изображении. Были варианты использования Tesseract, но была вероятность использования простого хостинга где не будет возможности установить дополнительный софт. Проанализировав доступные средства на GitHub нашел несколько реализаций, но они были на мой взгляд, то слишком сложные, то не простые для быстрой интеграции. В общем свой велосипед ближе и милей.
Класс поддерживает только текст написанный на монотонном фоне, без перемешивания строк. Такие изображения он не обработает:


В первом случае из-за разноцветного фона, во втором из-за того что строчки пересекаются. Скрипт разрабатывался для распознавания номеров телефонов на изображении. С чем он и справляется. Для обработки текста изначально он разрезается на строки, слова и символы в словах. Для отделения объектов текста от фона текст выделяется на разнице отличия яркости текста и яркости фона. Как правило фон является доминирующим цветом на изображении, для выявления его соберем все цвета и примем цвет который чаще всего встречается за фон изображения. В изображениях формата JPG частенько встречаются размытия, шумы, для устранения их мы возьмем и удалим все смежные цвета с фоном которые входят в диапазон от цвет фона до цвет фона — 20%. Оставшиеся цвета присвоим тексту. После того как мы определились какого цвета текст, а какого фон мы разделяем изображение на строки. Строки с текстом будут темнее чем меж строчные интервалы, после того как мы вычислим строки, нам нужно нарастить по 20% для захвата букв которые выходят за рамки темной полосы текста. Такие буквы как заглавные и у, р, б и т.д. Так же, для того чтоб подчеркнуть яркость текста мы утолщаем его обходя все изображение и расширяя текст.

Подобный метод разделения на объекты можно применить к словам и буквам, для этого нужно перевернуть изображение на 270 градусов и учесть что между словами интервал больше чем между буквами.
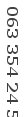

Разбив текст на буквы приступаем к распознаванию. Для этого нам нужно создать шаблоны для символов. В генераторе шаблонов применяется тот-же алгоритм разделения, но с дополнительным сведением одинаковых символов. Для создания более точных шаблонов необходимо задать погрешность в символах, обычно это до 10%, в этом случае мы выиграем в списке одинаковых символов при создании шаблона. Погрешность задается вызовом метода Recognizer::setInfelicity(10). Чем больше будет образцов для анализа тем лучше. Сам генератор располагается по адресу ./template_generator/generator.php
После запуска у вас должна появиться форма с изображениями и текстовым полем для ввода расшифровки этого изображения:

Заполнив форму и нажав кнопку Gen вам в браузере выведется шаблон в JSON формате, его нужно сохранить в нужном для вас месте под понятным именем, для подключения его вам нужно задать папку в котором хранится шаблон и его имя с помощью функции Recognizer::setTemplateDir(dirName) Recognizer::loadTemplate(name).
Каждый символ приводится в формат 15×16 и выглядит в форматированном виде:
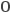
000000000000000
000001111000000
000011111100000
000110000111000
001100000011000
011100000011100
011100000011100
011100000011100
011100000011100
011100000011100
011100000011100
011100000011100
001100000011000
000110000111000
000111000110000
000011111100000
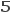
000000000000000
001111111110000
011111111110000
011000000000000
011000000000000
011000000000000
011000000000000
011111110000000
011111111000000
000000001110000
000000000110000
000000000110000
000000000110000
011000001110000
011111111100000
001111111000000
При сравнении берется значение из шаблона и сравнивается с распознаваемым символом, у того символа который лучше всего совпадет и присваивается значение шаблона, если не удалось распознать, то подставится вопросительный знак.
Код применения класса:
<?php
require_once __DIR__ . '/bootstrap.php';
use bpteam\phpOCR\Recognizer;
use bpteam\phpOCR\Img;
$file_name = __DIR__ . '/template/test_img/olx1.png';
$ex = 'png';
Recognizer::setInfelicity(10);
$img = Recognizer::openImg($file_name);
//Source image
echo "<br>Step 0 src img<br>";
Img::show($img,$ex,100);
//load template
$name = 'olx';
Recognizer::setTemplateDir(__DIR__ . '/template/');
$template = Recognizer::loadTemplate($name);
// OCR
echo "<br>defineImg<br>";
$text = Recognizer::read($file_name, $template);
echo $text."<br>";
Код класса можно форкнуть в моем профиле на GitHub gd2-php-ocr.